Why hasn’t AI automated away more professions? One way of investigating this question is to compare the skills that real jobs require with current AI systems’ capabilities. As long as there’s a gap between these two, full automation is unfeasible.
One important limitation is that AI systems cannot yet act coherently over long periods of time. While AI has demonstrated impressive capabilities in solving concrete, isolated problems, maintaining consistent goals, reasoning, and plans over extended time frames has proven more challenging.
We know AI systems are getting better at completing tasks over longer time horizons, as METR’s recent work shows. But how much better will they need to get to start having real economic impact, or at least for their automation capabilities to increase significantly?
To answer this, we define sequential coherence as an AI system’s ability to maintain consistent performance across extended task sequences. We estimate its importance as a bottleneck for automation by measuring the time needed to complete all remotable tasks in the O*NET dataset. Our findings suggest that AI agents could have enough sequential coherence to perform any remote economic task by 2030, and that AI automation potential could increase discontinuously.
What is Sequential Coherence?
Recent discussions about AI economics have highlighted that while LLMs are useful assistants that have increased worker productivity, their effects in terms of full-job automation have yet to be felt. The explanations offered usually invoke ‘agency’, ‘autonomy’, ‘coherence’, or ‘adapt plans to circumstances’—concepts that are never clearly defined.
We define sequential coherence as the AI system’s ability to maintain consistent performance quality across extended sequences of steps or interactions. The degree of sequential coherence required by a task is measured by the number of sequential steps or subtasks needed to complete it. When other factors are held constant, tasks requiring more steps demand higher sequential coherence. This explains why current AI systems excel at individual problems but struggle with complex, multi-step tasks—they hit a sequential coherence ceiling where performance degrades as step count increases, regardless of the difficulty of each individual step.
Illustrating Sequential Coherence
To illustrate our definition of sequential coherence, we present five examples. Through these examples, we motivate the idea that sequential coherence is indeed an ability that current AI systems struggle with and that this ability is important for automating away entire occupations.
Example #1: Teaching Economics
Consider teaching an economics course. While occupational databases like O*NET might list ‘teach economic theories’ as a single task, this decomposes into numerous subtasks: planning a syllabus, preparing lectures, delivering explanations, answering questions, recognising confusion, adjusting content dynamically, and grading assignments. Current AI systems might handle individual subtasks well, preparing slides or answering factual questions, but cannot deliver a coherent semester-long course.
Yet the challenge isn’t computational complexity alone. Teaching requires maintaining thematic consistency across subtasks, adapting to cumulative student understanding, and revising strategies based on feedback. Even if an AI could excel at each individual subtask, current systems lack the coherence to coordinate these activities consistently over an entire semester.
Example #2: Empirical Evidence from Simple Tasks
Our first empirical example comes from Timothy B. Lee, who devised a clean test of sequential coherence using sequential marble-moving problems. He prompted:
‘Alice put 1 marbles into the Red jar.
Frank took a marble out of the jar with the most marbles.
David put 4 marbles into the Blue jar.
Frank took half the marbles out of the Blue jar and put them in the Purple jar.
Frank took 1 marble out of the Blue jar…’
Lee’s prompt consists of a concatenation of very easy tasks, and arguably the only difficulty is not losing focus and keep going for as long as you need to. Lee reports that OpenAI’s model GPT-4o could solve problems like this with up to 50-70 steps, while o1 struggled with problems that had 250 steps. This suggests that models are improving at sequential coherence, but also that the number of steps of a problem seems like a limitation of current AI models. Later, we will return to why models struggle with the number of steps, or why they have sequential coherence limitations.
Example #3: Context Rot in Conversations
The second empirical example involves what Hacker News user Workaccount2 recently termed ‘context rot’—the observation that conversations with LLMs tend to degrade in quality as the context window fills up. While this phenomenon has not been rigorously measured, anecdotal reports from X users suggest it is a common experience. This pattern again indicates that the number of steps in a task (in this case, the number of prompts in a conversation) poses a challenge to LLM performance.
As for the reason why step complexity might constrain AI systems, some observers suggest that LLMs struggle to filter relevant information effectively, instead getting distracted by extraneous details. As their context windows accumulate more information, they become increasingly likely to lose focus on the core problem they are trying to solve. Thus, sequential coherence is an area where humans maintain an advantage over LLMs in the near term, as people can prioritise relevant information and maintain focus on core objectives even when working with extensive background context.
Example #4: AI Agents and Complex Games
The empirical examples discussed so far focus on LLMs in their chatbot form. What about AI agents? Although clean tests of sequential coherence for AI agents are more difficult to construct, emerging examples suggest that AI agents struggle similarly with extended task sequences.
A notable case is Claude’s attempt to play Pokemon, where Claude Sonnet 3.7 showed significant improvement over its predecessors but still could not complete the game. Claude exhibited several characteristic failures: repeatedly trying to talk to trainers it had already beaten, searching for non-existent exits by moving along solid walls, and consistently choosing obvious trap routes over correct paths simply because they appeared closer.
This example is less definitive for our purposes because the underlying causes of Claude’s struggles remain unclear. Memory constraints seem unlikely given the extensive scaffolding provided. The failures could stem from deficits in common sense reasoning, executive function, or even vision processing. The vision hypothesis is supported by Gemini’s successful completion of Pokemon Blue despite comparable gameplay abilities to Claude, with superior vision processing being their primary scaffolding difference (Gemini could ‘see’ the game better). This diagnostic ambiguity illustrates the challenge of isolating sequential coherence limitations from other potential factors when evaluating agents.
Vending-Bench offers one benchmark that tries to capture this concept. The benchmark tests LLMs’ capacity for sustained decisionmaking over long time horizons by putting agents in a simulated environment where they must operate a vending machine business. Each individual task in the simulation—setting prices, placing orders, checking inventory—is relatively simple, but agents must coordinate these activities coherently across hundreds of simulated days, which appears to capture sequential coherence as we have defined it.
The results show interesting patterns. The most advanced models like Claude 3.5 Sonnet and o3-mini sometimes achieve better results (measured in net worth) than human baselines, but with extremely high variance across runs. The researchers also found that agents systematically decreased their use of available functions–like sending emails to suppliers, checking inventory, or restocking the machine—after around 120 days of simulation. This decline in active business management suggests models gradually lose focus on their goals rather than struggling with increasingly difficult tasks. The researchers also provide compelling evidence that agents struggle with information management over time: counterintuitively, agents with more memory performed worse than models with less memory—a finding the authors suggest reflects the general difficulty LLMs have with longer contexts and filtering relevant information.
We think Vending-Bench represents a step in the right direction for measuring sequential coherence, and the results definitely demonstrate that tasks over long time horizons challenge even the most advanced agents. However, as we saw with Claude playing Pokemon, the benchmark appears to capture other factors beyond purely sequential coherence. The paper notes that models frequently fail due to what might be described as common-sense failures or reasoning errors. In one of Claude Sonnet 3.5’s runs, for instance, the model achieved low sales and profits because it mistakenly attributed its poor performance to the vending machine’s location rather than its own inventory mismanagement. Meanwhile, o3-mini simply forgot how to correctly call the functions needed to manage its business. These examples illustrate how challenging it can be to isolate purely sequential coherence abilities from other cognitive limitations in agentic tasks.
Example #5: Systematic Evidence from METR Results
Despite these measurement difficulties, our final example offers more systematic evidence that sequential coherence underlies AI agents’ struggles with long-horizon tasks. Toby Ord’s analysis of recent METR results reveals that a simple exponential function accurately models the relationship between AI success rates and the time humans need to complete tasks.
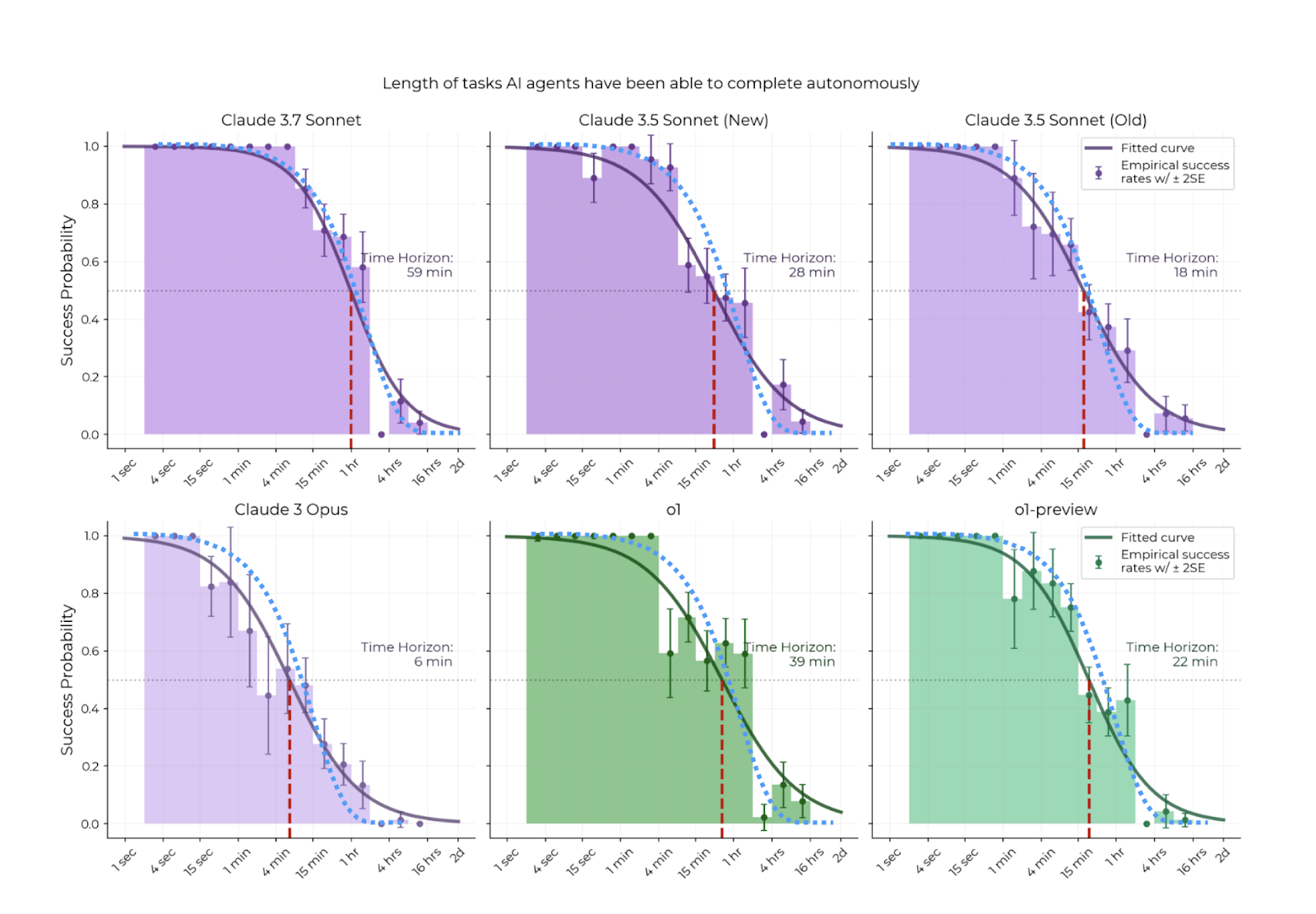
This pattern connects directly to sequential coherence through a simple mechanism: tasks decompose into sequential subtasks where failure at any single step causes overall failure. As task duration increases, and with it the number of constituent steps, AI success rates decay exponentially, demonstrating that sequential coherence limitations represent a fundamental bottleneck for real-world AI impact.
Ord’s analysis reveals why this exponential relationship emerges and points toward a second origin for sequential coherence limitations. Many tasks have O-Ring properties, meaning failure at any single subtask causes the entire task to fail. Current AI systems struggle to recognise and correct their mistakes, so when they fail a subtask, they cannot recover and the whole task fails. If AI systems could effectively self-correct during extended sequences, we would expect the exponential decay to break down. The persistence of this pattern suggests that the core limitation lies in maintaining coherent error recovery over long horizons rather than in solving individual subtasks.
Measuring coherence
Sequential coherence is an ability that comes in degrees. Given our definition of sequential coherence, we interpret recent work by METR as showing that AI systems are getting better at it, and at a rapid pace. But this, by itself, does not tell us how important these advances are in terms of AI task automation potential. It could be that, as METR’s projections show, by 2026 we have systems capable of completing tasks over an 8-hour time horizon. But if most tasks in the economy require much more coherence than this, then sequential coherence will still be a bottleneck. To understand how big of a challenge sequential coherence will be for task automation, we need a measure of the importance of sequential coherence in the economy.
Unfortunately, as we have mentioned above, measuring sequential coherence directly is challenging—no established metric categorises long-term projects by saying ‘this task requires X months of coherence’ or ‘that task requires Y years of coherence’. For this reason, we use as a proxy for sequential coherence the time it would take a human to complete a given task autonomously. This is an imperfect measurement, but it’s supported by the simple heuristic that tasks requiring longer periods of sustained, autonomous human effort would also require more steps or substasks to be completed—and it’s also supported by Ord’s results discussed above in the case of AI systems. Further, by using this proxy, our results can be combined with METR’s results to produce additional insights on the possible economic impact of future AI agents. In the next section, we explain in more detail how we implement this proxy.
Methodology
To estimate the importance of sequential coherence in the economy, we used the O*NET database, which lists all tasks involved in each occupation for the US economy. We used Barnett 2025’s classification of remotable tasks because the near-term automation potential from AI comes mostly from agents that operate in digital environments.
We used Google’s Gemini 2.5 Flash model to estimate how much time it would take a human to perform them, excluding all waiting periods, if such an estimate was possible given the task description and details about the occupation.
To ground the model’s estimates, we manually estimated a hundred tasks, using data where possible, and changed the model and the prompt until the LLM’s estimates were sufficiently calibrated with our own. We hope to replace this in the future with proper experimental data.
Results
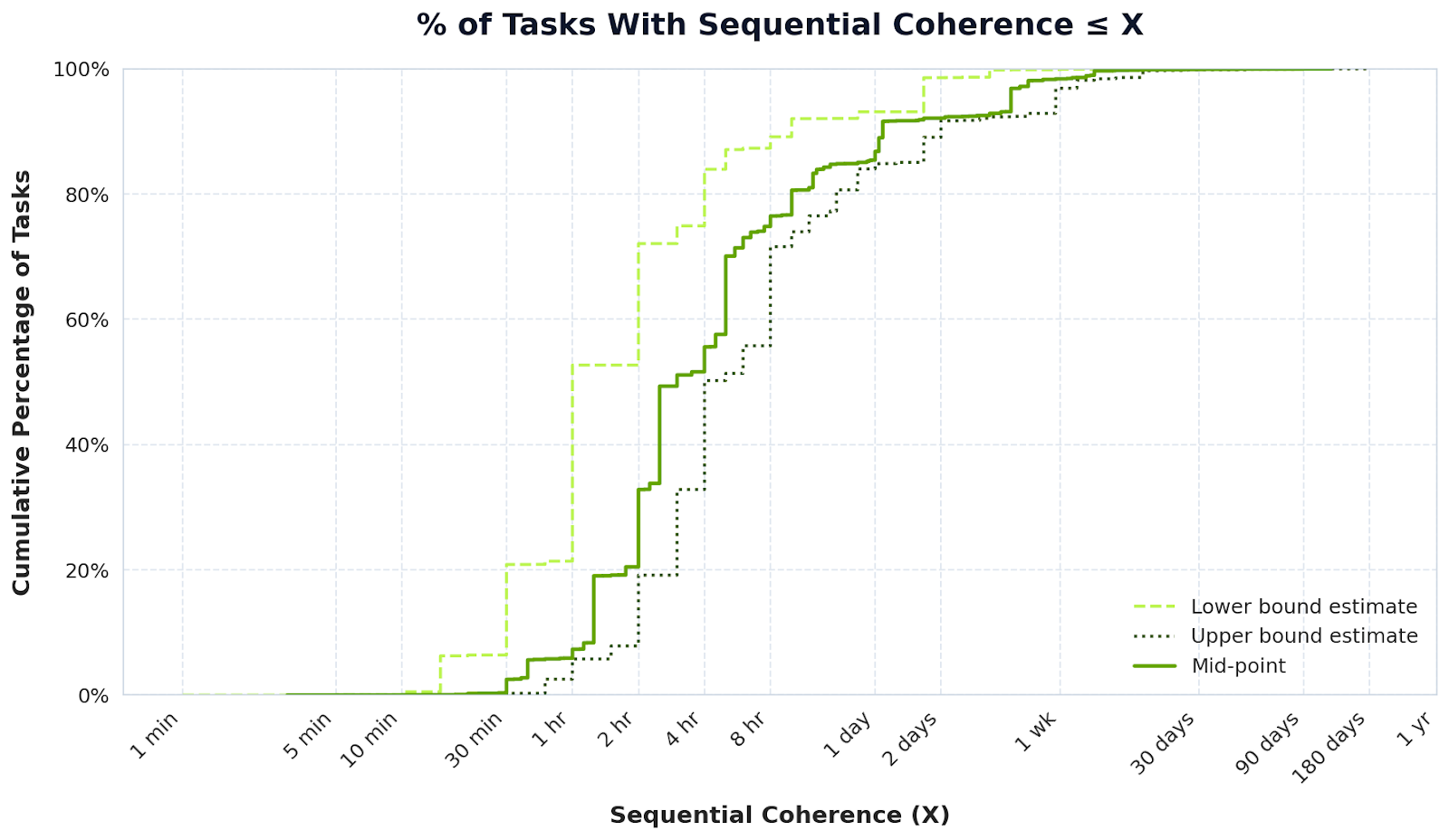
We summarise our main findings in two graphs. Figure 1 shows the distribution of tasks by the length of time taken to complete them. It shows that about 80% of tasks can be performed by humans with 8 hours of autonomous, effective work. Few tasks take more than a week, and just a handful of them go over 6 months.
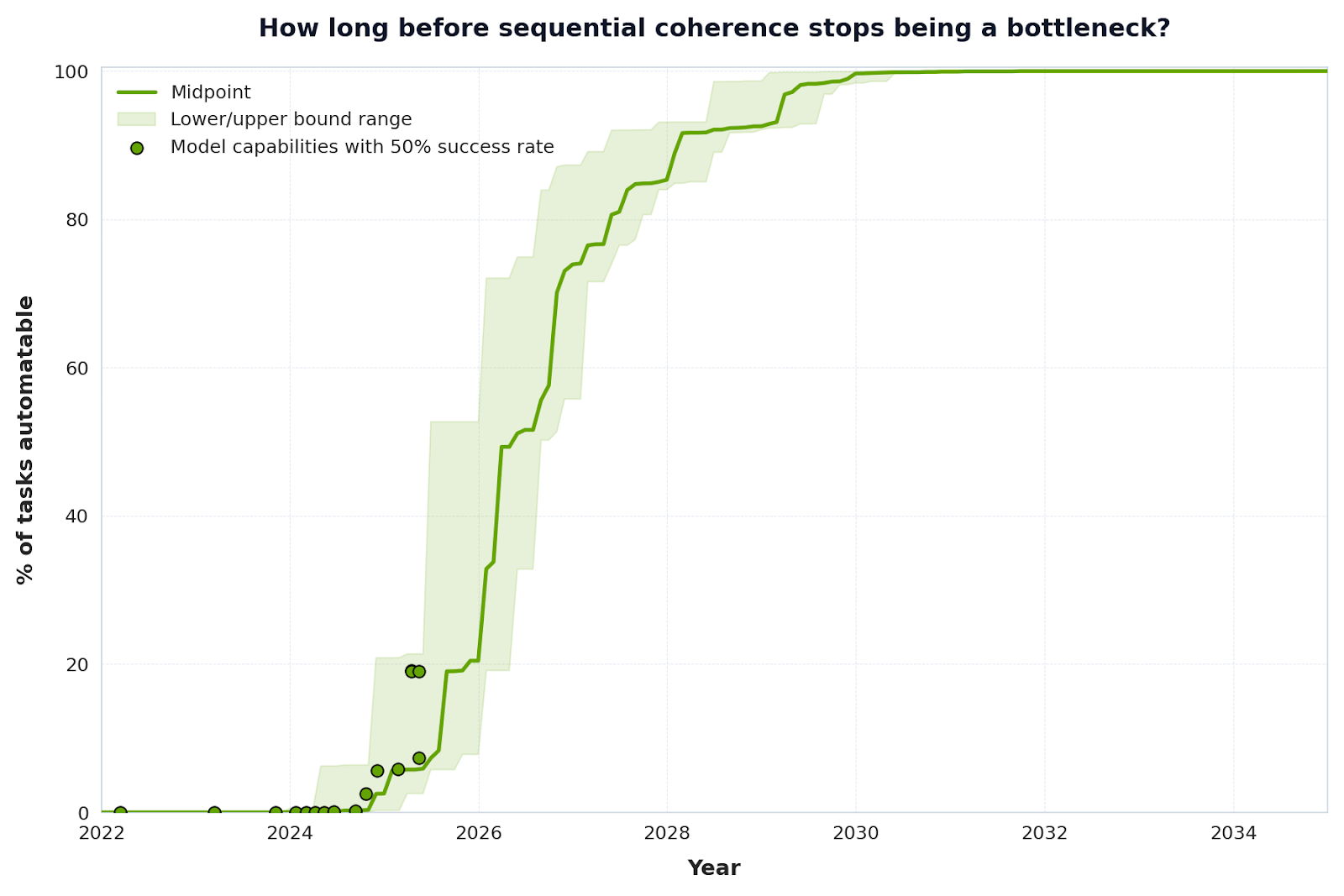
Humans arguably are quite good at sequential coherence. Figure 2 shows how good AIs are at it. It combines our estimates for task length with METR’s projections for the increase in coherence of AI models. The result is that by 2028, less than 20% of tasks will remain resistant to automation, if they depended only on our measure of coherence. By 2030, AI systems will have enough sequential coherence to essentially take over the US economy – again, if sequential coherence were the only bottleneck left to unhobble. More importantly, the change in AI automation potential is quick, going from nearly 20% of tasks in 2026 to near 100% in 2030.
Confidence
One question remains: how confident are we in estimates of task duration?
The LLM estimated half of all tasks to take between two to twenty hours, and three quarters of tasks to take less than or equal to 1 day on the lower end, and less than or equal to 6 days on the higher end. These estimates sounded reasonable for the O*NET tasks under analysis.
We found that 90% of task duration estimates have an upper to lower bound duration ratio lower than or equal to 10.
Tasks with very large ratios accurately reflect the ambiguity of the task description. For instance, the task ‘Conduct research in a particular field of knowledge and publish findings in professional journals, books, or electronic media’ takes between 40 hours and 1 year (216x difference).
Implications
Why should you care about these results? Our estimates of the distribution of task length for the US economy point to coherence being a less important factor than we expected. The fact that 80% of tasks can be completed in 8 hours or less suggests that, regardless of the actual importance of sequential coherence for unlocking economic value, this will not be a bottleneck for very long. When we combined our estimates with METR’s, which project the increasing capacity of AI agents to perform tasks over longer time horizons, we realised that by 2026, sequential coherence won’t be an issue for automating more than 60% of all tasks. This has potential policy implications that we do not explore in this piece, but seem particularly relevant for concerns about gradual disempowerment.
Our project has some important limitations, both theoretical and empirical. The caveats below offer room for improvement in future iterations of the project, as well as new lines of investigation.
Limitations of the theoretical approach
Sequential coherence as a concept
We define sequential coherence as the AI system’s ability to maintain consistent performance quality across extended sequences of steps or interactions. One objection that could be raised to the concept comes from the ‘jagged-frontier’ of AI systems. This is the observation that AI capabilities are very irregular—while they can perform tasks that would take a human many hours in mere seconds or minutes, they struggle with seemingly easy, short-term tasks that involve a fewer number of steps. Thus, the concept is not capturing everything that matters for tracking AI progress and its real-world implications.
Sequential coherence as a significant bottleneck
We make an additional claim: if AIs could act coherently over an arbitrary number of steps, more economic value would be unlocked than if any other ability was ‘solved’.
However, it is plausible to believe other abilities are equally or more important. These include memory, context, multimodality, learning by doing, and cooperation. We aim to dedicate more time to identifying the most important bottlenecks to job automation in our future research.
Task length as a proxy for coherence
Our proxy for sequential coherence is the length it would take a human to complete a given task. The idea behind using this proxy is that the longer the task, the more steps or subtasks it requires to be completed. But this is not a perfect measure. The proxy can be misleading when a task takes a lot of time for a human to complete not because it involves more steps, but rather because the subtasks are very long in themselves.
A related concern has to do with waiting times: a task can take a human a long time to complete because she has to wait for some time before continuing with the next step.
Limitations of the estimates of task length
LLM classification limitations
Humans have a hard time estimating how long something takes, and so do LLMs. In our test bench, we evaluated the consistency of the LLM’s answers, and found that the more the task statement seemed ambiguous, the more the model changed its estimate between a few values, but it ultimately stayed consistent amongst those values. This is why we give upper- and lower- bound estimates for task length.
In the future, we might try to gather experimental data on task length to calibrate the model, like METR did for software development tasks. We could also cross-validate the estimates by developing additional methods for time estimation. There is prior work in this area. We might also use a model harnessed with estimation tools, or spend time developing a larger validation set so that we can evaluate our prompt and model choices more accurately.
METR’s estimates
We use METR’s estimates on the increasing capacity of AI agents to perform longer time-horizon tasks, doubling every 7 months, to achieve the result that more than 60 per cent of tasks can be performed by AI agents by 2026 (at 50% success rate).
The problem with using those estimates is that they are based on a set of coding benchmarks, which, as others have commented, do not reflect the messiness of real-world work environments. Also, the extent to which we can extrapolate the performance of AI agents in coding tasks to other types of tasks is an open question, especially considering how reasoning models are particularly good at coding and math, as opposed to other fields.
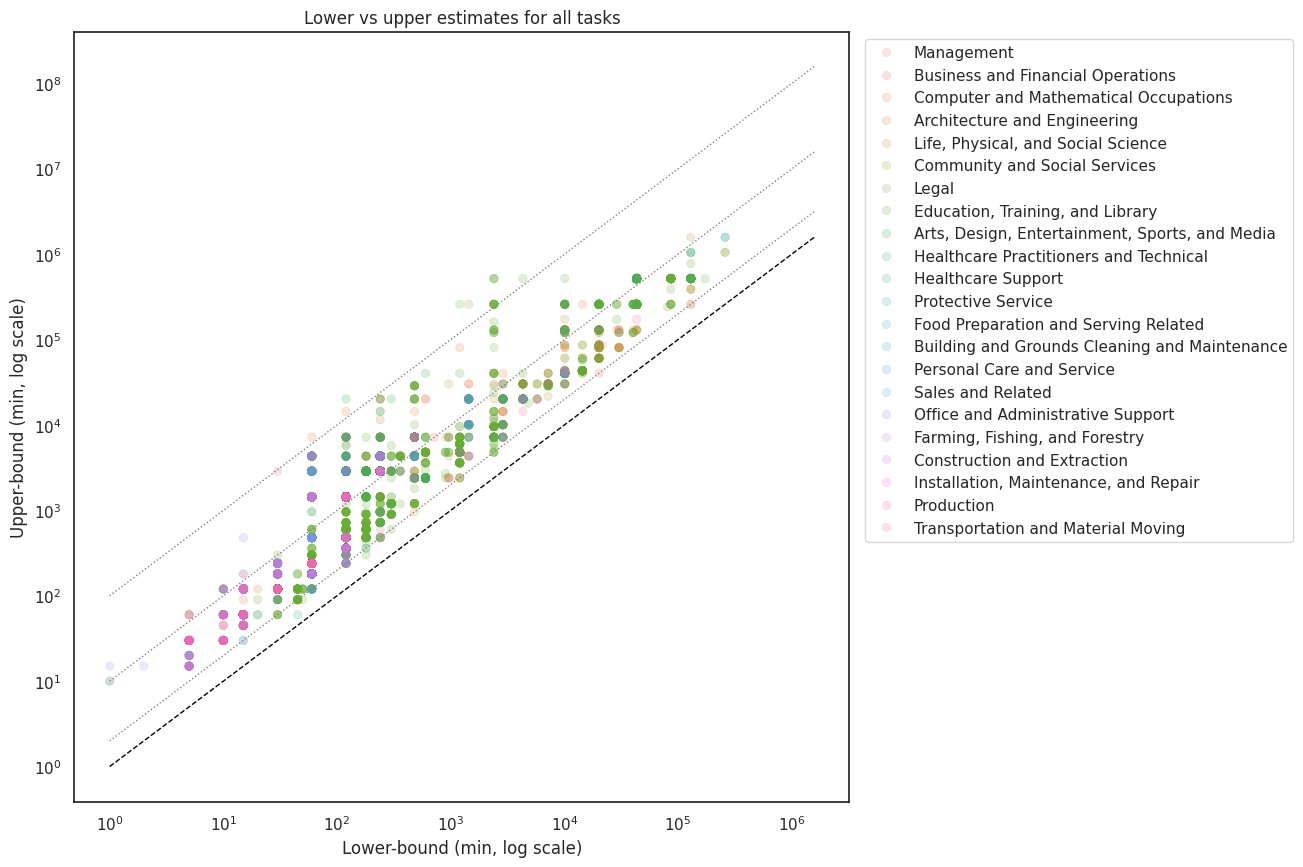
To see how much economic value could be unlocked if sequential coherence were solved, we investigated how much sequential coherence the five most remotable occupation groups required.
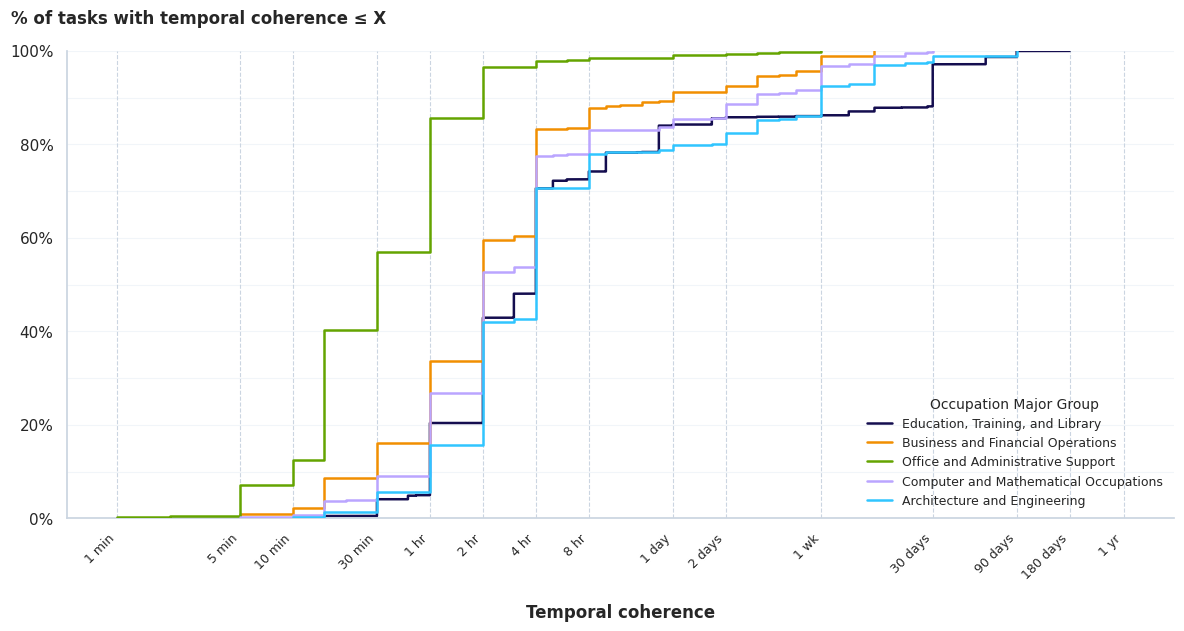
As shown in the graph above, all top five occupation groups, except for Architecture and Engineering, comprise 80% of tasks which can be completed in a day (8 hours of work). Because AI agents may achieve this level of sequential coherence in 2026 (according to METR’s projections), AI agents may be unlocking a tremendous amount of economic value. To get a rough sense for the magnitude, suppose we achieve enough sequential coherence for task automation. Then, if 80% of tasks in all of these occupations can be automated, this amounts to $3.72 trillion dollars of economic value. This is of course a simplification, but it illustrates how quickly AI could transform the economy thanks to improvements in sequential coherence.
This research was conducted as part of the Economics of Transformative AI hackathon with Apart Research.